Load data from a SQL database
This tutorial will show you how you can use dlt to load data from a SQL Database (PostgreSQL, MySQL, Microsoft SQL Server, Oracle, IBM DB2, etc.) into any dlt-compatible destination (Postgres, BigQuery, Snowflake, DuckDB, etc.).
To make it easy to reproduce, we will be loading data from the public MySQL RFam database into a local DuckDB instance.
What you will learn
- How to set up and configure a basic SQL database pipeline
- How to implement "append," "replace," and "merge" loading strategies
- How to load data incrementally
0. Prerequisites
- Python 3.9 or higher installed
- Virtual environment set up
- dlt installed. Follow the instructions in the installation guide to create a new virtual environment and install the
dltpackage.
1. Create a new dlt project
Initialize a new dlt project in your current working directory using the dlt init command:
dlt init sql_database duckdb
This is a handy CLI command that creates files and folders required for a SQL Database to DuckDB pipeline. You can easily replace duckdb with any other supported destinations.
After running this command, your project will have the following structure:
├── .dlt
│ ├── config.toml
│ └── secrets.toml
├── sql_database_pipeline.py
└── requirements.txt
Here’s what each file does:
sql_database_pipeline.py: This is the main script where you'll define your data pipeline. It contains several different examples for how you can configure your SQL Database pipeline.requirements.txt: This file lists all the Python dependencies required for your project..dlt/: This directory contains the configuration files for your project:secrets.toml: This file stores your credentials, API keys, tokens, and other sensitive information.config.toml: This file contains the configuration settings for yourdltproject.
When deploying your pipeline in a production environment, managing all configurations with the TOML files might not be convenient. In this case, we highly recommend using environment variables or other configuration providers available in dlt to store secrets and configs instead.
2. Configure the pipeline script
With the necessary files in place, we can now start writing our pipeline script. The existing file sql_database_pipeline.py already contains many pre-configured example functions that can help you get started with different data loading scenarios. However, for the purpose of this tutorial, we will be writing a new function from scratch.
Running the script as it is will execute the function load_standalone_table_resource(), so remember to comment out the function call from inside the main block.
The following function will load the tables family and genome.
def load_tables_family_and_genome():
# create a dlt source that will load tables "family" and "genome"
source = sql_database().with_resources("family", "genome")
# Create a dlt pipeline object
pipeline = dlt.pipeline(
pipeline_name="sql_to_duckdb_pipeline", # custom name for the pipeline
destination="duckdb", # dlt destination to which the data will be loaded
dataset_name="sql_to_duckdb_pipeline_data" # custom name for the dataset created in the destination
)
# Run the pipeline
load_info = pipeline.run(source)
# Pretty print load information
print(load_info)
if __name__ == '__main__':
load_tables_family_and_genome()
Explanation:
- The
sql_databasesource has two built-in helper functions:sql_database()andsql_table():sql_database()is a dlt source function that iteratively loads the tables (in this example,"family"and"genome") passed inside thewith_resource()method.sql_table()is a dlt resource function that loads standalone tables. For example, if we wanted to only load the table"family", then we could have done it usingsql_table(table="family").
dlt.pipeline()creates adltpipeline with the name"sql_to_duckdb_pipeline"with the destination DuckDB.pipeline.run()method loads the data into the destination.
3. Add credentials
To sucessfully connect to your SQL database, you will need to pass credentials into your pipeline. dlt automatically looks for this information inside the generated TOML files.
Simply paste the connection details inside secrets.toml as follows:
[sources.sql_database.credentials]
drivername = "mysql+pymysql" # database+dialect
database = "Rfam"
password = ""
username = "rfamro"
host = "mysql-rfam-public.ebi.ac.uk"
port = 4497
Alternatively, you can also paste the credentials as a connection string:
sources.sql_database.credentials="mysql+pymysql://rfamro@mysql-rfam-public.ebi.ac.uk:4497/Rfam"
For more details on the credentials format and other connection methods read the section on configuring connection to the SQL Database.
4. Install dependencies
Before running the pipeline, make sure to install all the necessary dependencies:
General dependencies: These are the general dependencies needed by the
sql_databasesource.pip install -r requirements.txtDatabase-specific dependencies: In addition to the general dependencies, you will also need to install
pymysqlto connect to the MySQL database in this tutorial:pip install pymysqlExplanation: dlt uses SQLAlchemy to connect to the source database and hence, also requires the database-specific SQLAlchemy dialect, such as
pymysql(MySQL),psycopg2(Postgres),pymssql(MSSQL),snowflake-sqlalchemy(Snowflake), etc. See the SQLAlchemy docs for a full list of available dialects.
5. Run the pipeline
After performing steps 1-4, you should now be able to successfully run the pipeline by executing the following command:
python sql_database_pipeline.py
This will create the file sql_to_duckdb_pipeline.duckdb in your dlt project directory which contains the loaded data.
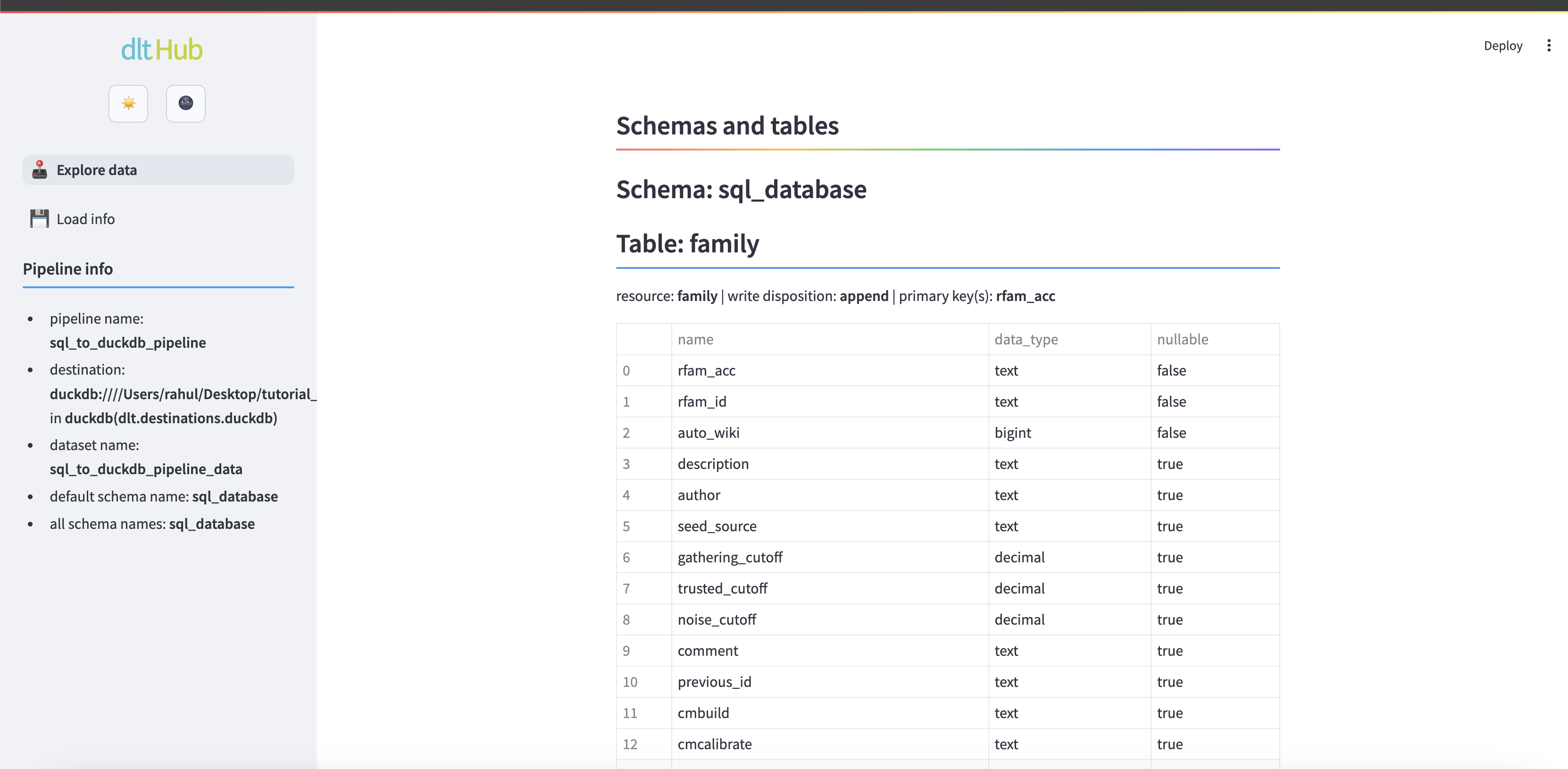
6. Explore the data
dlt comes with a built-in browser application that allows you to interact with the loaded data. To enable it, run the following command:
pip install streamlit
Next, run the following command to launch the data browser app:
dlt pipeline sql_to_duckdb_pipeline show
You can explore the loaded data, run queries and see some pipeline execution details.
7. Append, replace, or merge loaded data
Try running the pipeline again with python sql_database_pipeline.py. You will notice that
all the tables have the data duplicated. This happens as dlt, by default, appends data to the destination tables in every load. This behavior can be adjusted by setting the write_disposition parameter inside the pipeline.run() method. The possible settings are:
append: Appends the data to the destination table. This is the default.replace: Replaces the data in the destination table with the new data.merge: Merges the new data with the existing data in the destination table based on a primary key.
Load with replace
To prevent the data from being duplicated in each row, set write_disposition to replace:
def load_tables_family_and_genome():
source = sql_database().with_resources("family", "genome")
pipeline = dlt.pipeline(
pipeline_name="sql_to_duckdb_pipeline",
destination="duckdb",
dataset_name="sql_to_duckdb_pipeline_data"
)
load_info = pipeline.run(source, write_disposition="replace") # Set write_disposition to load the data with "replace"
print(load_info)
if __name__ == '__main__':
load_tables_family_and_genome()
Run the pipeline again with sql_database_pipeline.py. This time, the data will be replaced in the destination table instead of being appended.
Load with merge
When you want to update the existing data as new data is loaded, you can use the merge write disposition. This requires specifying a primary key for the table. The primary key is used to match the new data with the existing data in the destination table.
In the previous example, we set write_disposition="replace" inside pipeline.run() which caused all the tables to be loaded with replace. However, it's also possible to define the write_disposition strategy separately for each tables using the apply_hints method. In the example below, we use apply_hints on each table to specify different primary keys for merge:
def load_tables_family_and_genome():
source = sql_database().with_resources("family", "genome")
# specify different loading strategy for each resource using apply_hints
source.family.apply_hints(write_disposition="merge", primary_key="rfam_id") # merge table "family" on column "rfam_id"
source.genome.apply_hints(write_disposition="merge", primary_key="upid") # merge table "genome" on column "upid"
pipeline = dlt.pipeline(
pipeline_name="sql_to_duckdb_pipeline",
destination="duckdb",
dataset_name="sql_to_duckdb_pipeline_data"
)
load_info = pipeline.run(source)
print(load_info)
if __name__ == '__main__':
load_tables_family_and_genome()
8. Load data incrementally
Often you don't want to load the whole data in each load, but rather only the new or modified data. dlt makes this easy with incremental loading.
In the example below, we configure the table "family" to load incrementally based on the column "updated":
def load_tables_family_and_genome():
source = sql_database().with_resources("family", "genome")
# only load rows whose "updated" value is greater than the last pipeline run
source.family.apply_hints(incremental=dlt.sources.incremental("updated"))
pipeline = dlt.pipeline(
pipeline_name="sql_to_duckdb_pipeline",
destination="duckdb",
dataset_name="sql_to_duckdb_pipeline_data"
)
load_info = pipeline.run(source)
print(load_info)
if __name__ == '__main__':
load_tables_family_and_genome()
In the first run of the pipeline python sql_database_pipeline.py, the entire table "family" will be loaded. In every subsequent run, only the newly updated rows (as tracked by the column "updated") will be loaded.
What's next?
Congratulations on completing the tutorial! You learned how to set up a SQL Database source in dlt and run a data pipeline to load the data into DuckDB.
Interested in learning more about dlt? Here are some suggestions:
- Learn more about the SQL Database source configuration in the SQL Database source reference
- Learn more about different credential types in Built-in credentials
- Learn how to create a custom source in the advanced tutorial